ICL Demonstration Selection and Disentangling Task Recognition from Task Learning

In the realm of In-Context Learning (ICL) of Large Language Models (LLMs), previous works have revealed that demonstrations can be viewed as secretly performing gradient descent [1], and the output labels in the demonstrations don’t seem to matter as much as the other factors, except for the the larger models which can overcome semantic priors learned during pre-training when the input-output mappings to be learned from the demonstrations are novel [2].
A couple recent papers shed more light on these two fronts.
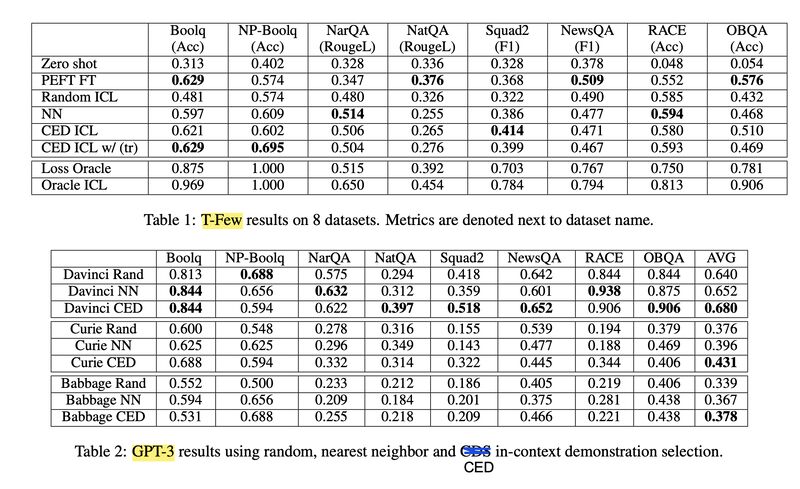
The first paper [3] connects the rich history of selecting training examples for domain adaptation via cross-entropy difference (CED; screenshot 1), with the finding that ICL performs implicit fine-tuning, to propose a new In-Context Demonstration (ICD) selection method. The ICD method first fine-tunes one model per training example via Parameter Efficient Fine-tuning (PEFT), then selects the training example whose fine-tuned model leads to the lowest perplexity score on a test example (screenshot 2). The results on both T-Few and GPT-3 show it mostly outperforms the Nearest Neighbor (NN) baseline and in some cases even PEFT fully fine-tuned on 256 examples (screenshot 3).

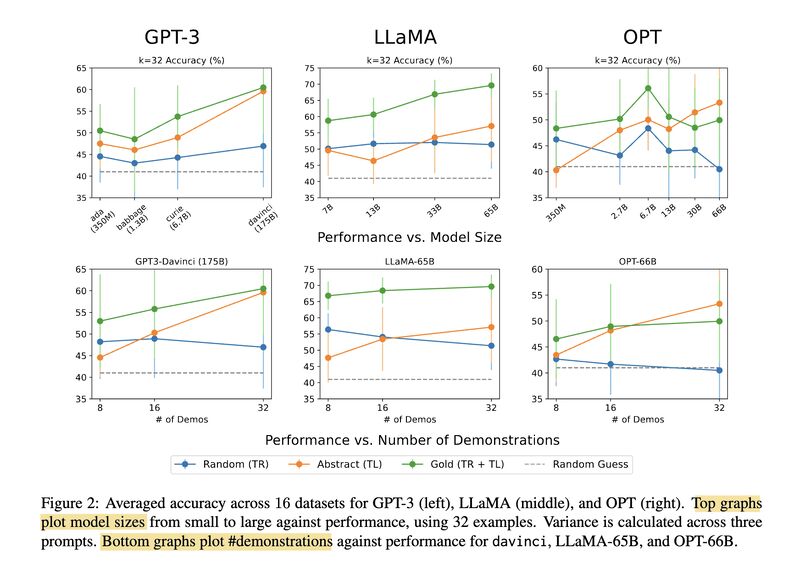
The second paper [4] digs deeper into the intriguing observation in ICL that the output labels don’t seem to matter much for a class of models, while novel input-output mappings can be learned better with LLMs. Through three experimental settings (screenshot 4): (1) RANDOM where the output labels are randomly picked, (2) ABSTRACT where the output labels are consistently mapped to abstract symbols, and (3) GOLD where the output labels are the original in-domain labels, they show ICL can be disentangled into two subtasks: Task Recognition (TR) and Task Learning (TL). TR (focused by the RANDOM setting) recognizes tasks from demonstrations and doesn’t improve as model size and number of demonstrations scale up, while TL (focused by the ABSTRACT setting) learns new input-output mappings and does improve with increasing model size and number of demonstrations (screenshot 5).

Originally posted on LinkedIn.
References
[1] Previous post: Why Does In-Context Learning Work?
[2] Previous post: Do Labels in ICL Demonstrations Actually Matter?
[3] Dan Iter, Reid Pryzant, Ruochen Xu, Shuohang Wang, Yang Liu, Yichong Xu, and Chenguang Zhu. 2023. “In-Context Demonstration Selection with Cross Entropy Difference.” https://arxiv.org/abs/2305.14726
[4] Jane P., Tianyu Gao, Howard Chen, and Danqi Chen. 2023. “What In-Context Learning ‘Learns’ In-Context: Disentangling Task Recognition and Task Learning.” https://arxiv.org/abs/2305.09731