Do Labels in ICL Demonstrations Actually Matter?
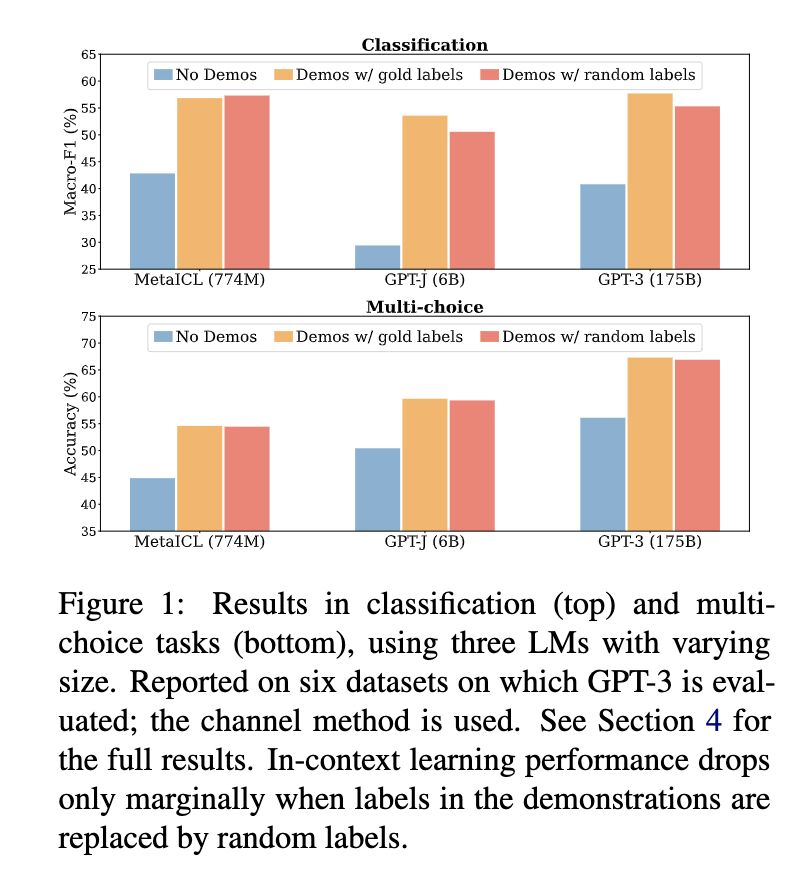
In-Context Learning (ICL) is a superpower LLMs have that allows them to learn a new task from inference-time demonstrations without the need of costly retraining. But can LLMs really overcome semantic priors learned from the pretraining and adapt to novel input-label mappings through just demonstrations? Two recent papers shed light on this for us:
Paper 1 shows that the labels in these demonstrations do not matter much. Replacing them with random labels works almost as well as long as there are demonstrations (screenshot 1)! In fact, the other aspects of demonstrations such as the label space (screenshot 2), the distribution of the input text (screenshot 3), and the overall demonstration format (screenshot 4), actually matter more!
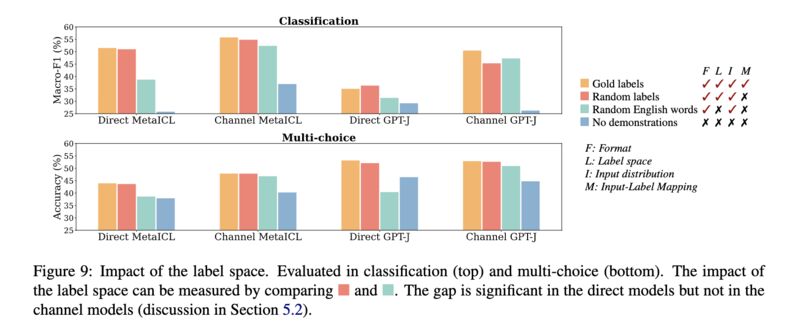
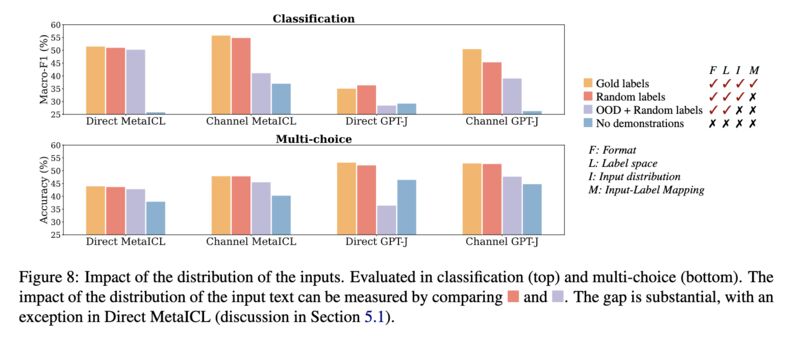
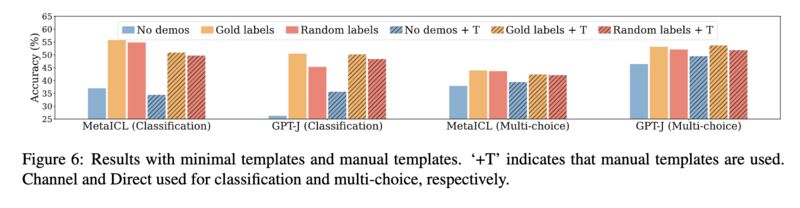
Paper 2 demonstrates that the ability to overcome semantic priors via demonstrations may be an emerging phenomenon with model scale. They show that when labels are flipped in the demonstrations, larger LLMs follow more closely than the smaller ones (screenshot 5), and when labels are swapped with semantically unrelated ones, smaller models suffer more in accuracy (screenshot 6).
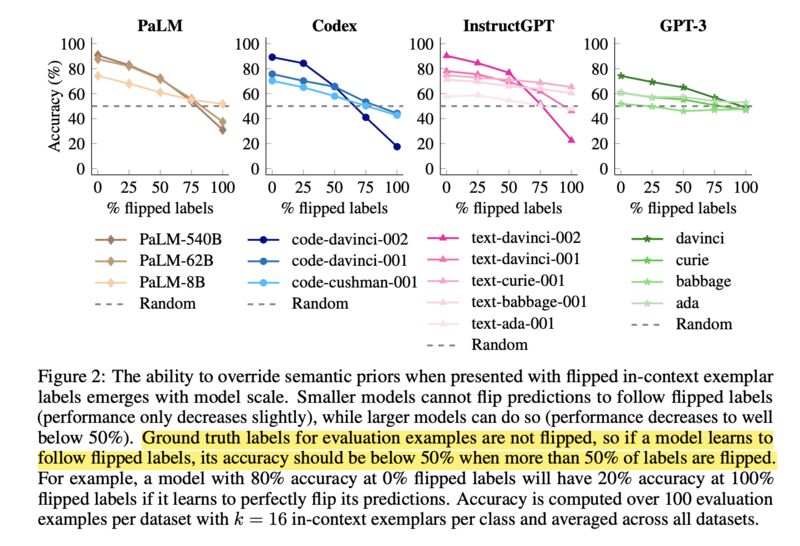
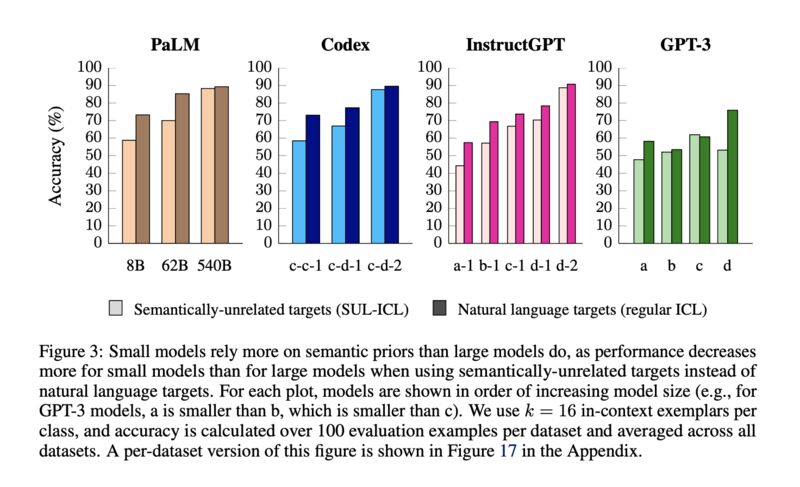
On the surface, these two papers seem to be at odds. While Paper 1 shows that labels do not matter much in ICL, Paper 2 shows they do, but only for larger models (Section 7). Curiously for GPT3, a model covered by both papers, the scaling effect did not show up in the label-flipping experiments (screenshot 5). For this reason, the authors (Paper 2)
“consider all GPT-3 models to be”small” models because they all behave similarly to each other in this way.”
;-)
Another note is that the paper discussed earlier on learnability of ICL (see [1]) seems to give theoretical support that random label flipping does not matter (Theorem 1). Can it explain the scaling phenomenon?
Paper 1: Sewon Min, Xinxi Lyu, Ari Holtzman, Mikel Artetxe, Mike Lewis, Hannaneh Hajishirzi, and Luke Zettlemoyer. 2022. Rethinking the Role of Demonstrations: What Makes In-Context Learning Work? [2]
Paper 2: Jerry Wei, Jason Wei, Yi Tay, Dustin Tran, Albert Webson, Yifeng Lu, Xinyun Chen, Hanxiao Liu, Da Huang, Denny Zhou, and Tengyu Ma. 2023. Larger language models do in-context learning differently. [3]
Originally posted on LinkedIn.
References
[1] Previous post: Why Does In-Context Learning Work?
[2] Sewon Min, Xinxi Lyu, Ari Holtzman, Mikel Artetxe, Mike Lewis, Hannaneh Hajishirzi, and Luke Zettlemoyer. 2022. “Rethinking the Role of Demonstrations: What Makes In-Context Learning Work?” https://arxiv.org/abs/2202.12837
[3] Jerry Wei, Jason Wei, Yi Tay, Dustin Tran, Albert Webson, Yifeng Lu, Xinyun Chen, Hanxiao Liu, Da Huang, Denny Zhou, and Tengyu Ma. 2023. “Larger language models do in-context learning differently.” https://arxiv.org/abs/2303.03846