Filesystems vs. RAG
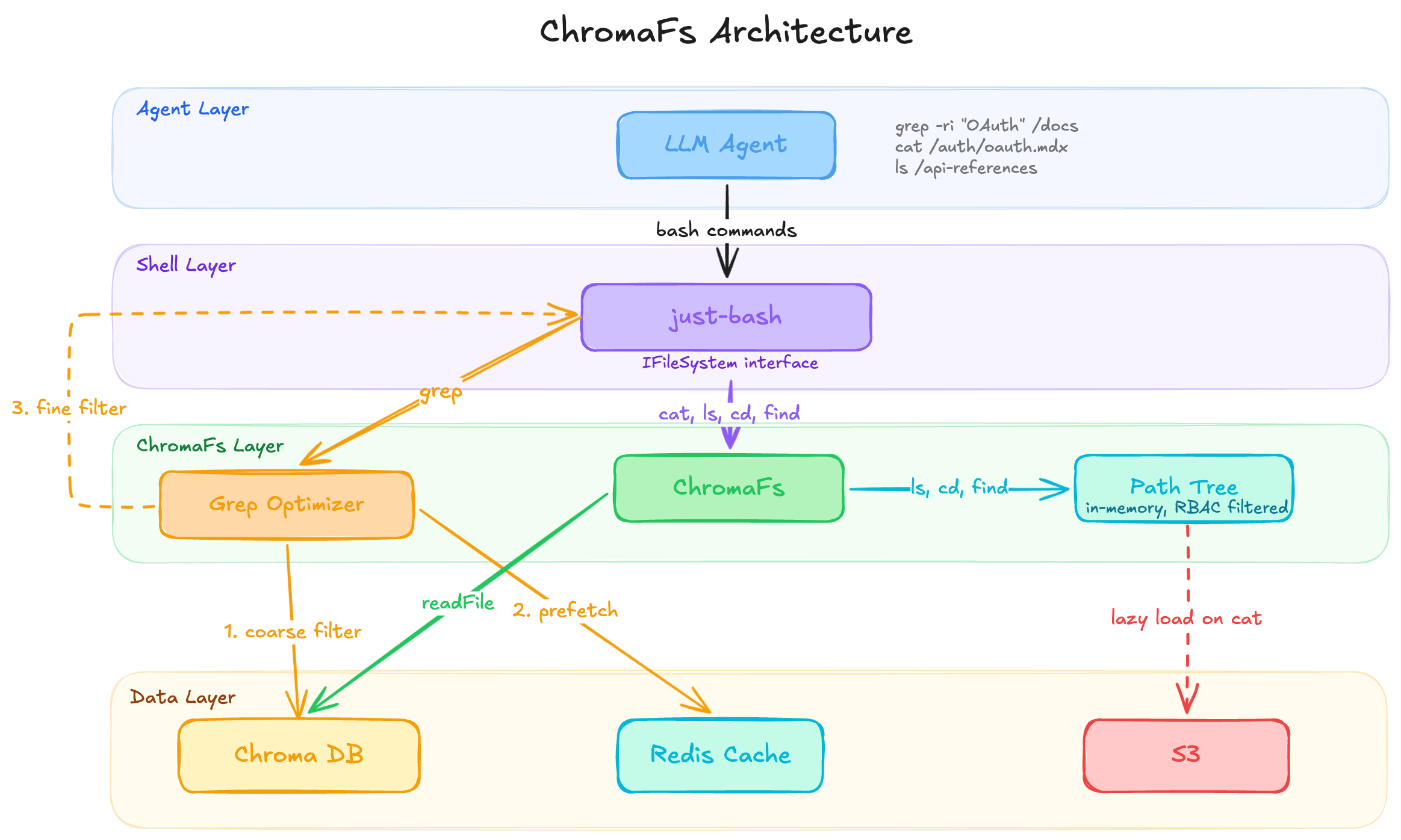
Can we replace RAG with filesystems? This article shares a neat engineering write-up on doing exactly that: replacing a standard docs RAG flow with a virtual filesystem for an assistant [1]. Instead of only retrieving top-K chunks, they let the model interact with documentation through familiar file operations like ls, cat, find, and grep. Under the hood, they built a virtual layer over their existing docs index, avoiding the latency and cost of spinning up full sandboxes while giving the assistant a more natural way to explore the corpus. Optimization details aside, the article hints at two bigger ideas. First, the filesystem vs. RAG distinction is really about structured navigation vs. relevance retrieval. A filesystem presents the corpus as a pre-built navigable structure for exploration. Plain RAG presents it as a retrieval space. Second, system interfaces work better when they align with the interaction patterns the base LLM already knows. For coding-oriented models especially, files, paths, directories, and shell-style operations are much closer to the environments they were trained on than a one-shot retrieve-and-insert workflow. The article explicitly framed the goal as letting the assistant explore docs the way a developer explores a codebase. A few contrasts between the filesystem and RAG approaches:
- Filesystems preserve and expose author-created structure that chunk RAG often weakens.
- Filesystem agents are natively iterative and exploratory; plain RAG is often, but not always, more one-shot.
- Filesystems provide a richer tool surface than retrieval alone.
- Filesystems are better for exact search, full-page reading, and multi-page investigation.
- Filesystems support hypothesis-driven exploration across documents: inspect one page, discover a term, search for it elsewhere, and refine understanding.
- Filesystems preserve document integrity better by making whole pages or files accessible, rather than only isolated retrieved chunks.
- Filesystem-based interfaces can align access control more naturally with paths, files, and directories, so the assistant’s visible world is scoped up front.
But RAG still shines when the main problem is semantic recall: messy corpora, weak or ambiguous structure, heterogeneous sources or modalities, or cases where a few relevant passages are enough and full exploration would be overkill. The interesting part is that these approaches are not incompatible. RAG can be one tool inside a filesystem-style agent: useful for candidate recall, while the filesystem layer handles navigation, inspection, and verification. The implementation described effectively does this by using existing indexing infrastructure to narrow search before exact filtering. Takeaway: RAG retrieves likely evidence. A filesystem lets the model investigate the source material. We can combine both.
References
[1] Mintlify. “How we built a virtual filesystem for our Assistant.” Mintlify Blog, March 24, 2026. https://www.mintlify.com/blog/how-we-built-a-virtual-filesystem-for-our-assistant
Originally posted on LinkedIn.