Learning to Reason in 13 Parameters
AI
LLMs
reasoning
generative AI
fine-tuning
links
TinyLoRA: an 8B Qwen2.5 reaches 91% on GSM8K with only 13 trained bf16 parameters — 26 bytes of learned weights.
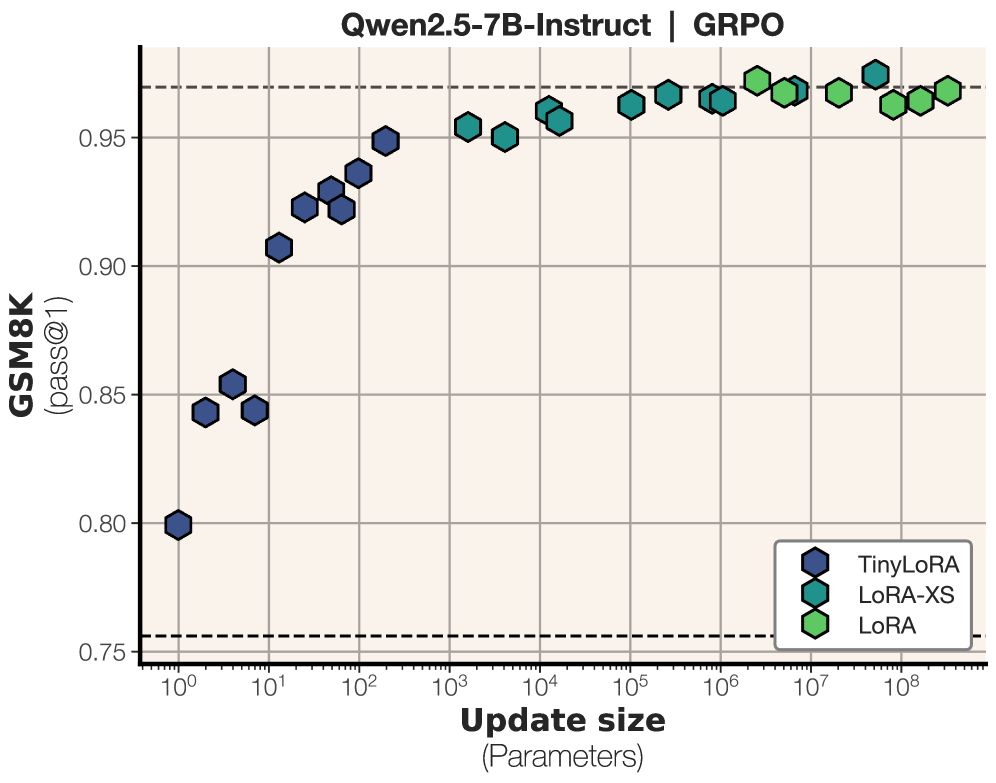
TinyLoRA pushes low-rank adaptation down to almost nothing [1].
- They report that an 8B-parameter Qwen2.5 model reaches 91% on GSM8K with only 13 trained bf16 parameters, which they note is just 26 bytes of learned weights.
- For RL-based post-training, the effective update needed to unlock better reasoning may live in a very low-dimensional subspace.
- This works well with RL, but not nearly as well with SFT, where they say SFT needs 100–1000x larger updates to match the same gains.
References
[1] “Learning to Reason in 13 Parameters.” arXiv. https://arxiv.org/abs/2602.04118
Originally posted on LinkedIn.