Embedding Limits: A Linear-Algebra Note (and Kernel Tricks)
AI
LLMs
RAG
embeddings
retrieval
RecSys
search
paper
research
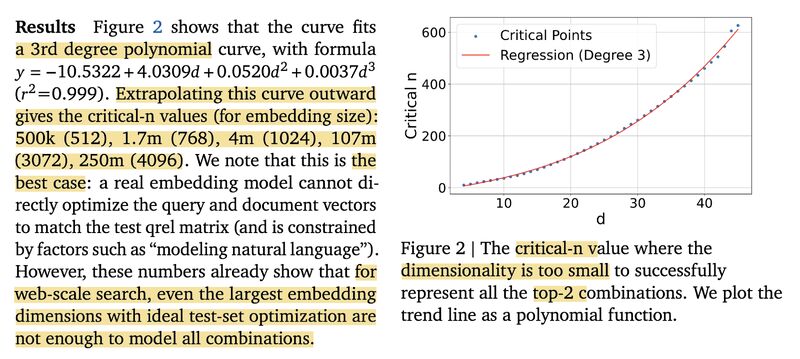
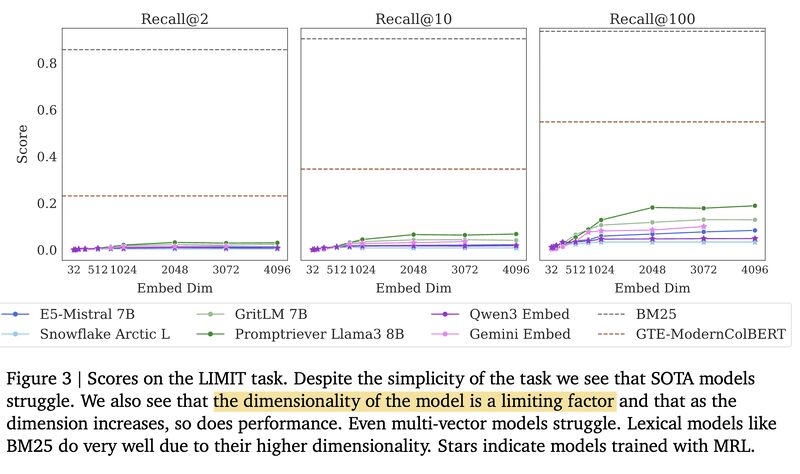
A follow-up callout: the bound rests on rank(AB) ≤ min(rank(A), rank(B)) — a property of dot-product scoring, not embeddings per se. Plus one more way out: kernel tricks.
A follow-up to Embeddings Hit a Theoretical Ceiling.
An important callout about this paper: many posts miss that the proof of limitation rests on a basic linear algebra fact: rank(AB) ≤ min(rank(A), rank(B)). This is a constraint of using dot product / cosine similarity for relevance scoring, not an inherent limit of embeddings themselves. Even bilinear models or learned similarity matrices still fall under this bound.
The paper suggests several ways out: multi-vector representations, late interaction models, and cross-encoders. And I’ll add one more: classic ML offers kernel tricks like Gaussian RBF that can break the embedding dimension bottleneck.
Curious to hear: how would the field tackle the bottleneck?

Originally posted on LinkedIn.