Embeddings Hit a Theoretical Ceiling

Embeddings are the beating heart of modern AI, from powering RAG (Retrieval Augmented Generation) systems that ground LLMs in external knowledge, to serving as the memory substrate for agentic AI. But a recent paper [1] shows they face a fundamental ceiling:
Theoretical bound: When relevance is computed via dot product, the number of distinct top-k retrieval sets is bounded by the embedding dimension d. If the relevance matrix (queries × docs) has sign-rank r, then d ≥ r is a hard requirement — no amount of training can avoid it.
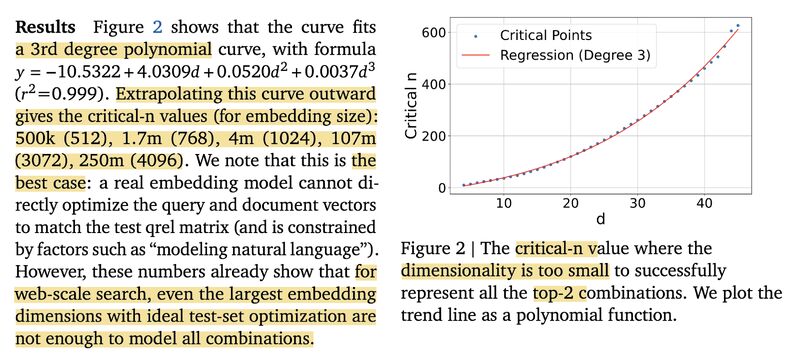
Oracle experiment: They empirically confirm this bound by directly optimizing embeddings (“free embeddings”) against the relevance matrix. The critical corpus size grows only cubically with dimension (see picture 1). For example, with embedding dimension d = 1024, you can only represent all possible 2-doc query combinations up to about 4 million documents — far below typical web-scale retrieval needs.
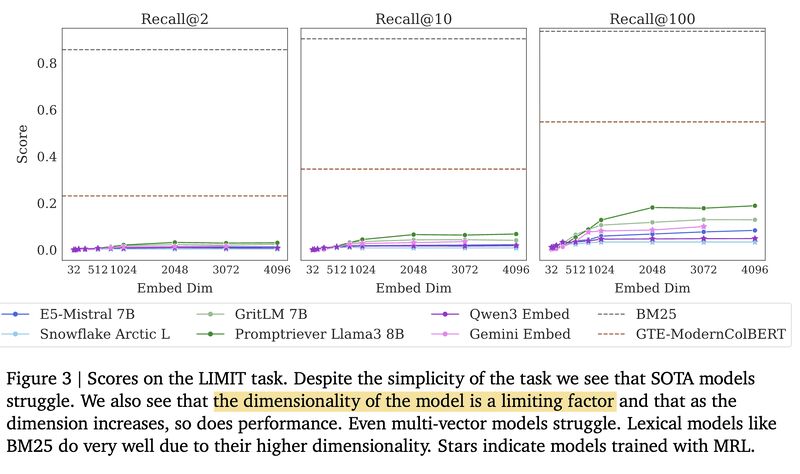
LIMIT dataset: To stress-test real models, they construct the LIMIT dataset consisting of 50k docs and 1k queries, each with 2 relevant docs (picture 2). All single-vector models fail badly, while BM25 and multi-vector methods perform much better (see picture 3).
Three ways out: (1) using cross-encoders, i.e., placing docs in the prompt for a Long-Context Language Model (LCLM), which is accurate but can be expensive, (2) using a multi-vector retrieval system, or (3) using a sparse retrieval system.
For the cross-encoder solution, this connects directly to our earlier work on Eliciting In-Context Retrieval and Reasoning (ICR²) [2], where we showed that a combination of training data design and model re-architecting can significantly improve retrieval performance (see picture 4). But many other directions remain open!
Follow-up: Embedding Limits: A Linear-Algebra Note (and Kernel Tricks).
References
[1] Weller, Orion, Michael Boratko, Iftekhar Naim, and Jinhyuk Lee. “On the theoretical limitations of embedding-based retrieval.” arXiv, 2025. https://arxiv.org/abs/2508.21038
[2] Qiu, Yifu, Varun Embar, Yizhe Zhang, Navdeep Jaitly, Shay Cohen, and Benjamin Han. “Eliciting In-Context Retrieval and Reasoning for Long-Context Large Language Models.” Apple Machine Learning Research, 2025. https://machinelearning.apple.com/research/eliciting-in-context · Repo: https://github.com/apple/ml-icr2
Originally posted on LinkedIn.