MAST: A Failure Taxonomy for Multi-Agent Systems

Multi-agent systems (MAS) promise enhanced capabilities through collaboration, but often fail to vastly outperform single-agent setups. What are their failure modes and how do we mitigate them?
A recent paper by Mert Cemri, Melissa Pan, Shuyi Yang, Lakshya A Agrawal, Bhavya Chopra, Rishabh Tiwari, Kurt Keutzer, Aditya Parameswaran, Dan Klein, Kannan Ramchandran, Matei Zaharia, Joseph Gonzalez, and Ion Stoica from University of California, Berkeley introduces MAST (Multi-Agent System Failure Taxonomy), the first empirically grounded framework for diagnosing MAS failures [1]:
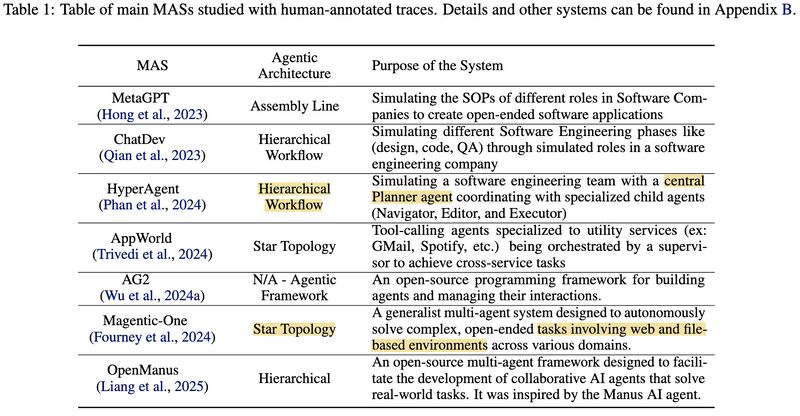
- They analyzed 7 popular MAS frameworks across 200+ tasks (picture 1).
- They identified 14 distinct failure modes across 3 categories (picture 2):
- Specification issues (e.g., poor prompt design, rigid turn-taking): 41.77%
- Inter-agent misalignment (e.g., reasoning-action mismatches): 36.94%
- Task verification failures (e.g., premature termination): 21.30%
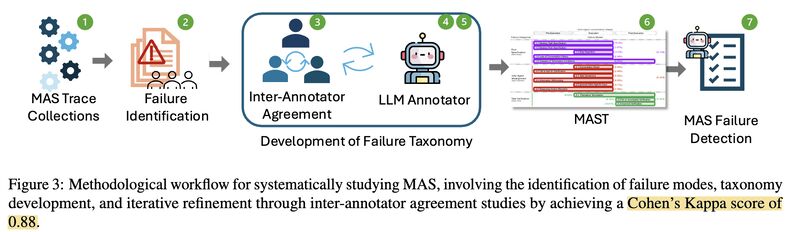
- Through rigorous development, MAST achieved Cohen’s Kappa 0.88 on inter-annotator agreement (picture 3).
- An automated LLM-as-a-Judge achieved 0.77 agreement with humans.
- They showed small interventions (like role clarification and verification steps) led to 9–16% improvements (picture 4).
MAST moves MAS development closer to science and engineering rather than guesswork.
References
[1] Cemri, Mert, et al. “Why Do Multi-Agent LLM Systems Fail?” arXiv, 2025. https://arxiv.org/abs/2503.13657
Originally posted on LinkedIn.