Time-Sensitive Knowledge Editing via Efficient Fine-Tuning (ACL 2024)
Updating time-sensitive knowledge in LLMs is crucial to ensure accuracy in downstream tasks. One approach we discussed previously is model editing, i.e., directly modifying model weights to inject or modify knowledge (Model editing: performing digital brain surgery). This type of approaches such as ROME and MEMIT, however,
- … requires estimation of large covariance matrices leading to stability issues;
- … requires locating layers for optimization which is difficult to scale;
- … produces models performing poorly on multi-hop question answering (QA).
In ACL 2024 next week, Hugh Ge will present how we can perform efficient fine-tuning for better knowledge editing (KE; picture 1):
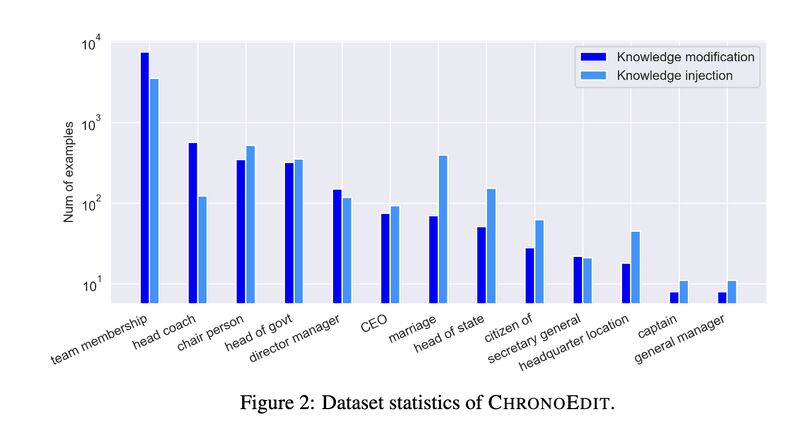
- We first construct a large-scale KE dataset “ChronoEdit” from Apple’s open-domain knowledge graph for training and testing (picture 2).
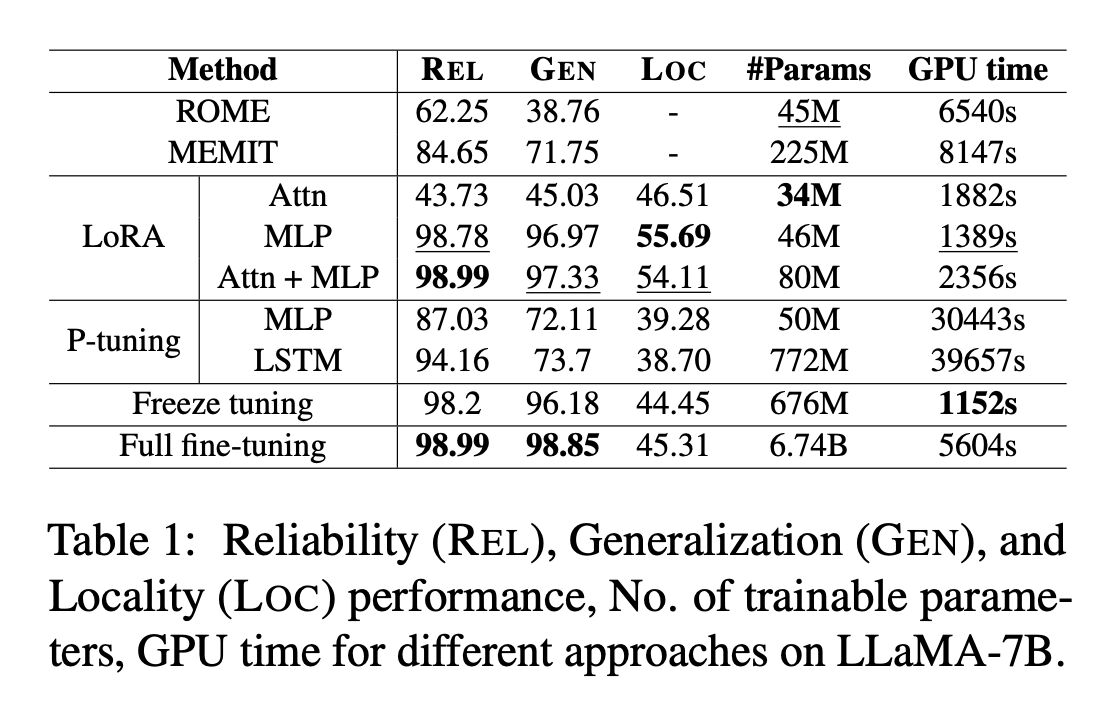
- We then show fine-tuning is effective in knowledge modification and injection (picture 3).
- In particular, applying LoRA on MLP and attention parameters is robust to number of edits (picture 4).
- Our results also show tuning middle layers are more important in improving multi-hop QA accuracy (picture 5).
References
[1] Ge, Hugh, Ali Mousavi, Edouard Grave, Armand Joulin, Kun Qian, Benjamin Han, Mostafa Arefiyan, and Yunyao Li. “Time Sensitive Knowledge Editing through Efficient Finetuning.” ACL 2024. https://machinelearning.apple.com/research/time-sensitive-finetuning
Abstract: Large Language Models (LLMs) have demonstrated impressive capability in different tasks and are bringing transformative changes to many domains. However, keeping the knowledge in LLMs up-to-date remains a challenge once pretraining is complete. It is thus essential to design effective methods to both update obsolete knowledge and induce new knowledge into LLMs. Existing locate-and-edit knowledge editing (KE) method suffers from two limitations. First, the post-edit LLMs by such methods generally have poor capability in answering complex queries that require multi-hop reasoning. Second, the long run-time of such locate-and-edit methods to perform knowledge edits make it infeasible for large scale KE in practice. In this paper, we explore Parameter-Efficient Fine-Tuning (PEFT) techniques as an alternative for KE. We curate a more comprehensive temporal KE dataset with both knowledge update and knowledge injection examples for KE performance benchmarking. We further probe the effect of fine-tuning on a range of layers in an LLM for the multi-hop QA task. We find that PEFT performs better than locate-and-edit techniques for time-sensitive knowledge edits.
Originally posted on LinkedIn.