LAGRANGE: Cyclic Evaluation for KG-Text Datasets
AI
LLMs
NLP
knowledge graphs
evaluation
paper
generative AI
Our paper on automatic graph-aligned dataset construction — cyclic evaluation reveals data quality without ground-truth alignments.
Our paper on automatic knowledge-graph-aligned dataset construction is out! The main points [1]:
- We showed cyclic evaluation — the process of training GTG (graph-to-text-to-graph) or TGT using a graph-aligned dataset, reflects faithfully the same trend a unidirectional evaluation does. It is therefore a better way to assess data quality because it does not rely on knowing ground truth matches!
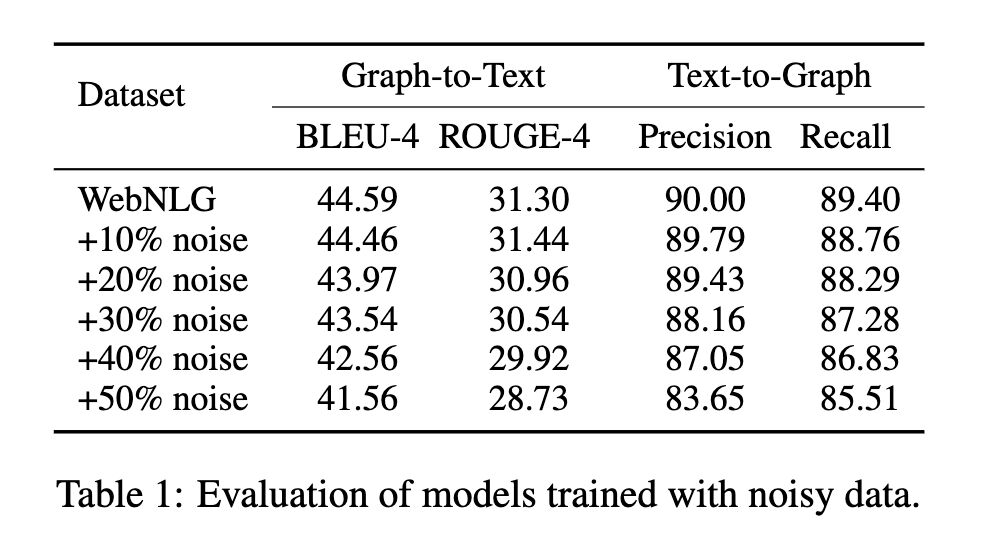
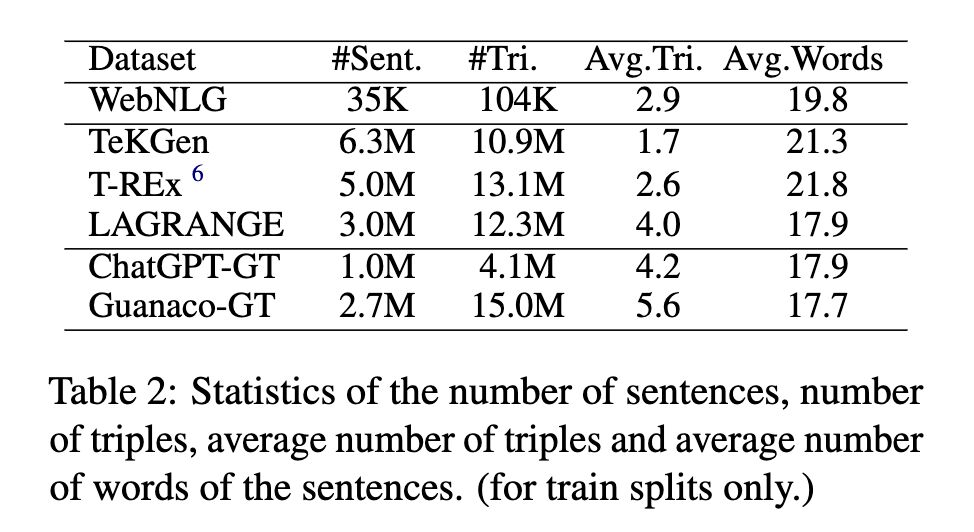
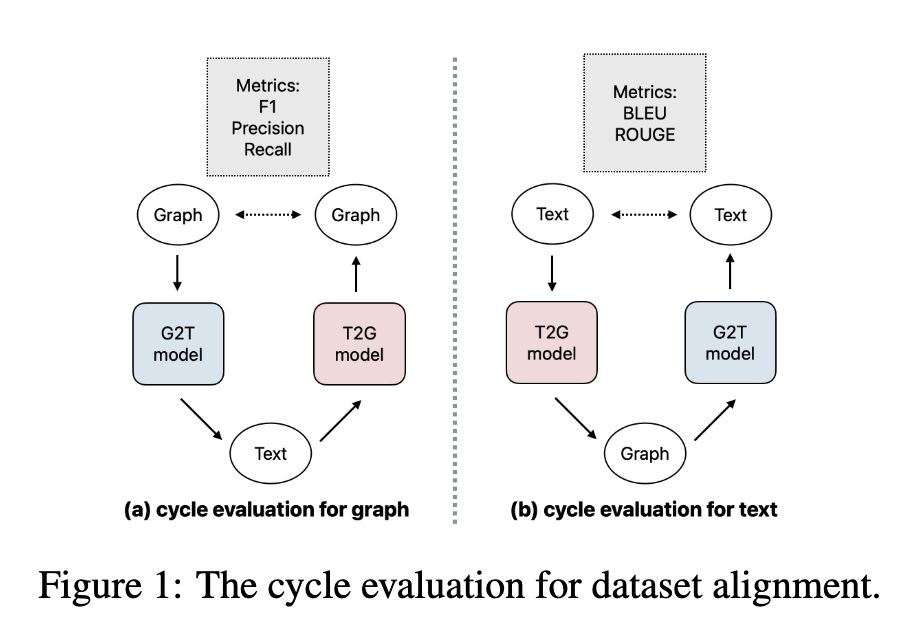
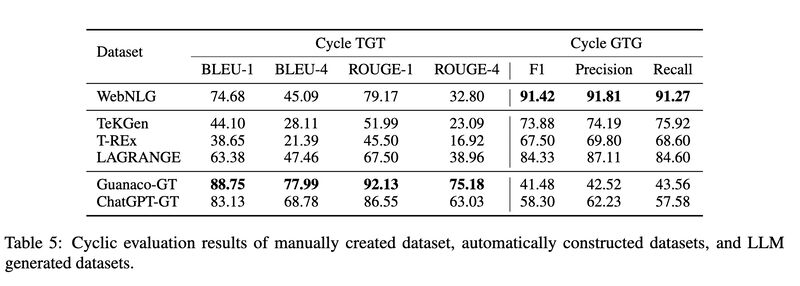
- We constructed a large graph-aligned dataset called LAGRANGE, and showed when used to train a T5-large model it performs the best among the automatically constructed datasets, even outperforming the manually constructed dataset WebNLG on BLUE-4 and ROUGE-4, and outperforming LLM-generated (ChatGPT and Guanaco) datasets on graph construction metrics.
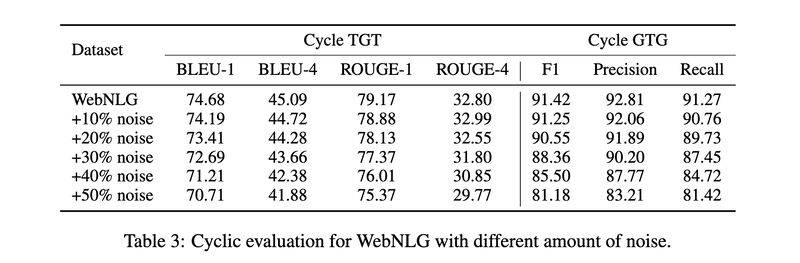
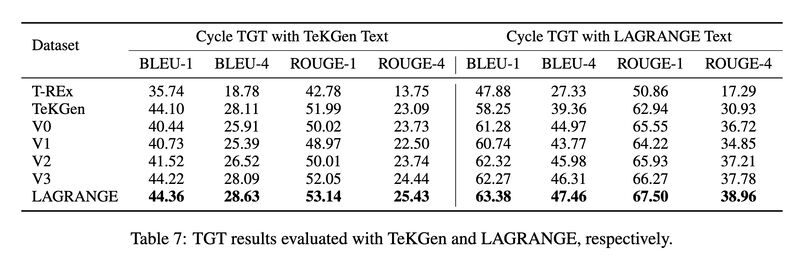
- For out-of-distribution evaluation, we showed LAGRANGE-trained models, when subject to two separate cyclic evaluations using TeKGen and LAGRANGE datasets, respectively, outperform the models trained with the other automatically constructed datasets, even the one for which train and test distributions match (TeKGen). The consistency in model rankings between these two cyclic evaluations also confirm the stability of the evaluation methodology.
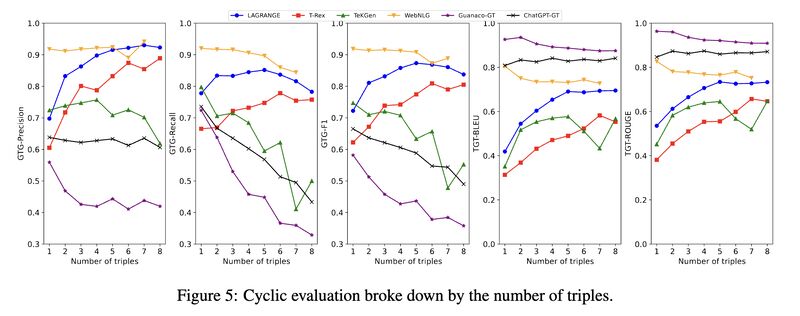
Originally posted on LinkedIn.
References
[1] Ali Mousavi, Xin Zhan, He Bai, Peng Shi, Theodoros Rekatsinas, Benjamin Han, Yunyao Li, Jeff Pound, Joshua Susskind, Natalie Schluter, Ihab Ilyas, and Navdeep Jaitly. “Construction of Paired Knowledge Graph-Text Datasets Informed by Cyclic Evaluation.” 2023. https://arxiv.org/abs/2309.11669