LLM-Generated Code Has a Serious API Misuse Problem
How robust and reliable is the code generated by LLMs, especially for real-world software development? A recent work [2] constructed a new benchmark based on [1] to evaluate if the generated code uses API correctly. Four popular LLMs – GPT-3.5, GPT-4, Llama 2, and Vicuna – are tested, and GPT-4 under zero-shot scored 62.09% misuse rate. Even with one-shot relevant examples the misuse rate of GPT-4 is 49.17%.


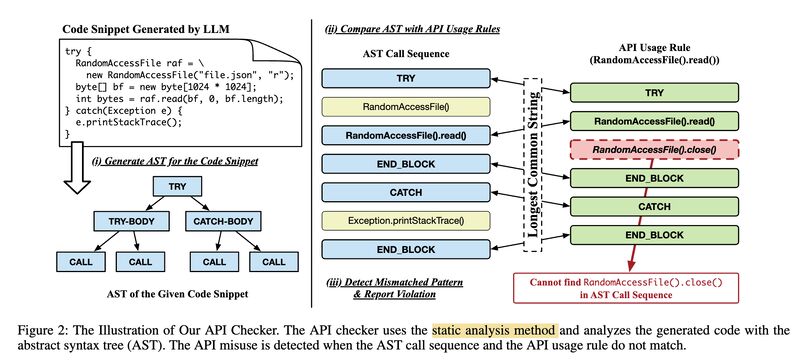
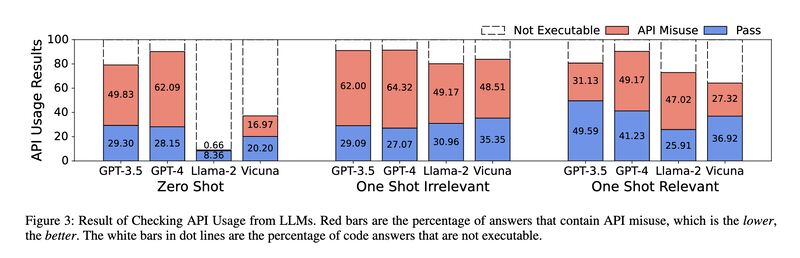
Since users of code generation with particular APIs are usually relatively inexperienced in the said APIs, these inaccuracies may have grave consequences to the robustness and reliability of the resulting software.
(How would Code Llama fare?)
Originally posted on LinkedIn.
References
[1] Tianyi Zhang, Ganesha Upadhyaya, Anastasia Reinhardt, Hridesh Rajan, and Miryung Kim. 2018. “Are code examples on an online Q&A forum reliable? a study of API misuse on stack overflow.” In Proceedings of the 40th International Conference on Software Engineering, pages 886–896, Gothenburg, Sweden. Association for Computing Machinery. http://dx.doi.org/10.1145/3180155.3180260
[2] Li Zhong and Zilong Wang. 2023. “A Study on Robustness and Reliability of Large Language Model Code Generation.” http://arxiv.org/abs/2308.10335