Model Collapse and LLM-Contaminated Training Data
Many have talked about the risks that can be brought by AI, or more specifically, generative AI: disinformation, job (in-)security, inequality, intellectual atrophy, even human extinction.
How about we add one more: it may spell the end of AI as we know it?
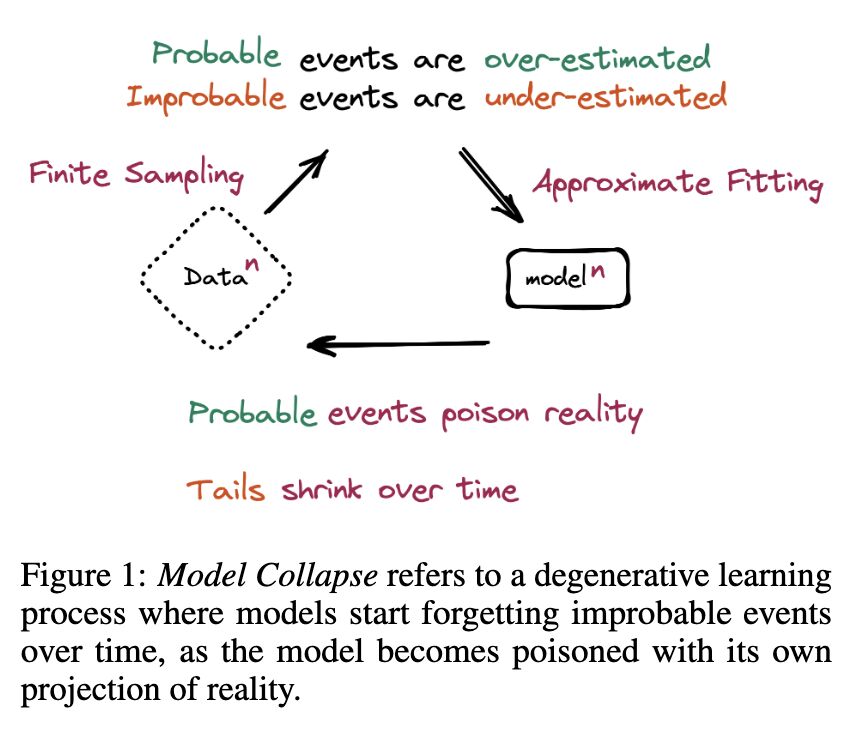
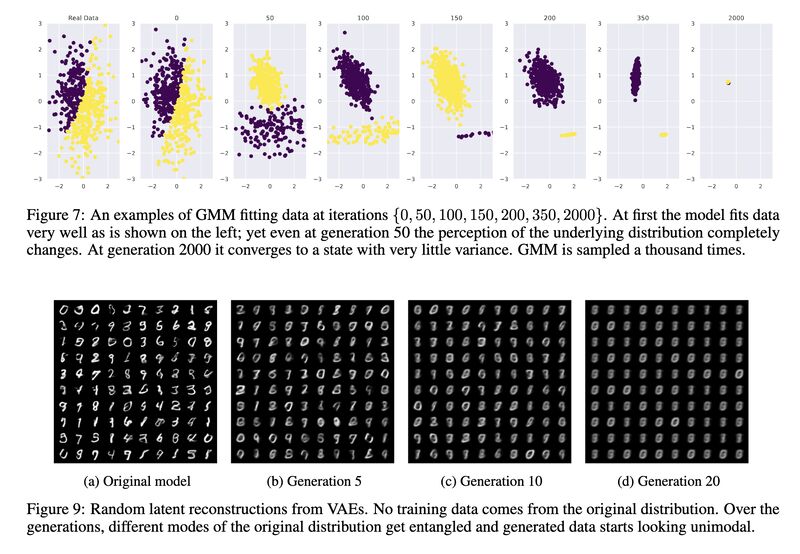
In [1] the researchers investigated a phenomenon they coin as “model collapse”: when models are trained on generated content from their past generations, irreversible defects start to appear (screenshot 1 & 2). Two main causes: statistical approximation error arises from finite sampling which leads to disappearing tails, and functional approximation error stems from insufficient expressive power of models which inevitably results in prediction errors (screenshot 3). Through theoretical analysis, the paper shows the average distance of the n-th generation from the original grows and can become infinite in the limit (see examples from screenshot 4).


So we just need to make sure we train our models with human annotated datasets, right?
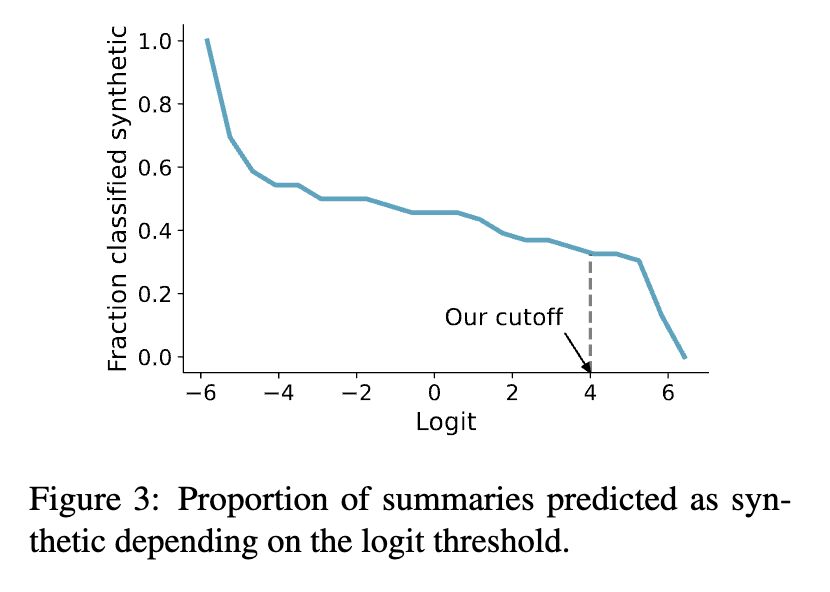
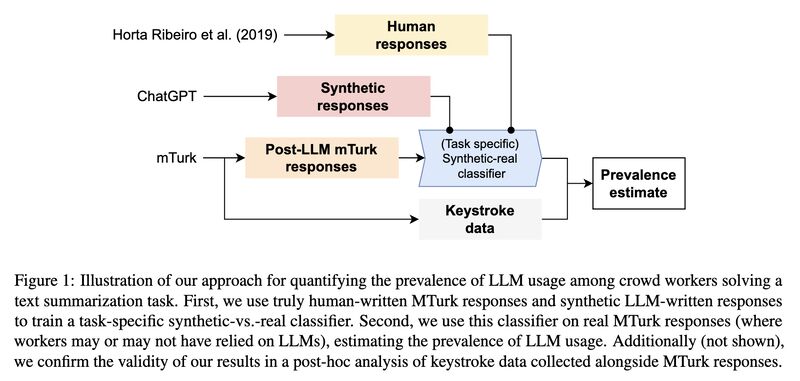
Unfortunately in this day and age, even that cannot be taken for granted. In [2] the researchers re-submitted a summarization annotation task to the crowd workers, and found 33-46% of them used LLMs to complete their tasks (screenshot 5). Their method is a combination of a trained classifier capable of telling synthetic and real texts apart with high accuracy (97-99% F1) and the use of keystroke data collected via Javascript (screenshot 6). The icing on the cake: they concluded that the reason why the synthetic-real classifier is so accurate is because of the lack of diversity in ChatGPT’s summarization output — imagine we train models on that!
Originally posted on LinkedIn.
References
[1] Ilia Shumailov, Zakhar Shumaylov, Yiren (Aaron) Zhao, Yarin Gal, Nicolas Papernot and Ross Anderson. 2023. The Curse of Recursion: Training on Generated Data Makes Models Forget. http://arxiv.org/abs/2305.17493
[2] Veniamin V., Manoel Horta Ribeiro and Robert West. 2023. Artificial Artificial Artificial Intelligence: Crowd Workers Widely Use Large Language Models for Text Production Tasks. http://arxiv.org/abs/2306.07899