The Core Challenges Facing Agentic AI Today
There has been a lot of excitement around AgenticAI these days, with powerful large language models (#LLMs) serving as the centerpiece for building autonomous agents capable of solving complex tasks. Auto-GPT [1] is one notable example, powered by GPT4. In [2], Han Xiao provides a great list of challenges facing such an approach at the current time:
Costs: One task is estimated to cost $14.4.
The divide between development and production: The knowledge gained by accomplishing one task cannot be reused for another similar task.
GPT4 as a problem-solving orchestrator is insufficient and often gets stuck: It has trouble decomposing problems, finding the best base cases, understanding contexts, and figuring out commonalities between problems (screenshot 1).
It lacks modern software engineering primitives such as asynchronous processing and inter-process communication among agents.

The core problem, of which I’d argue all of the above are symptoms, lies in using a model trained with linguistic datasets but expecting it to perform extra-linguistic tasks, such as planning. So how do LLMs fare in planning, for example? A recent paper [3] offers a comprehensive investigation (screenshot 2) and found that they exhibit much worse performance than generally perceived (screenshot 3).

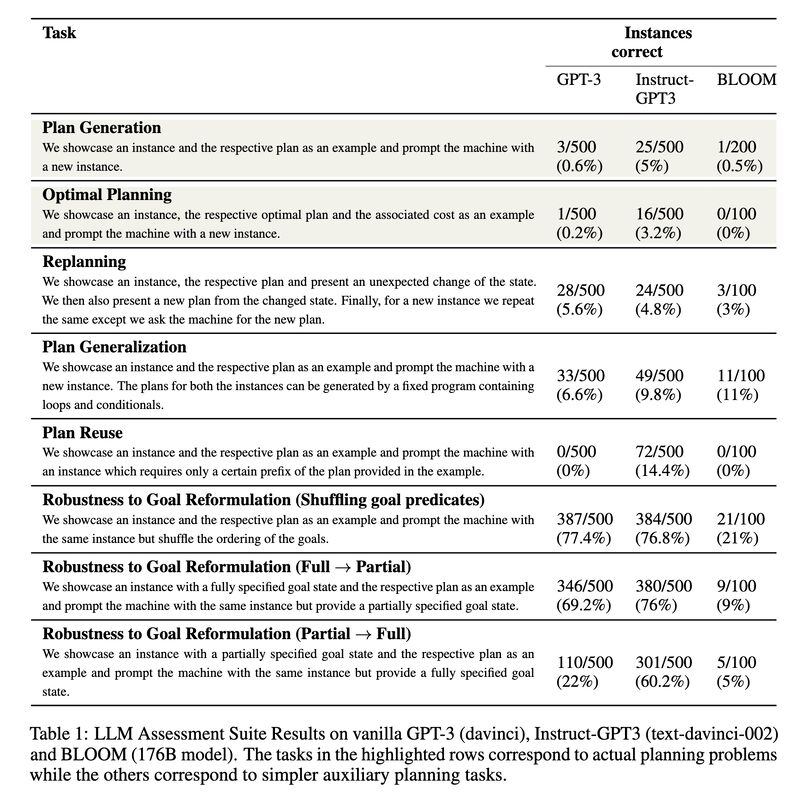
Perhaps we should approach agentic AI in a more holistic way, not placing a current-day generative model at the center and tasking it as the planner and reasoner. Rather, as Yoav Goldberg pointed out in [4], we should strive for modularity where the core knowledge about language and reasoning (and others) is separated but interconnected.
(X-post on Mastodon)
Originally posted on LinkedIn.
References
[1] Auto-GPT. 2023. https://github.com/Significant-Gravitas/Auto-GPT
[2] Han Xiao. 2023. “Auto-GPT Unmasked: The Hype and Hard Truths of Its Production Pitfalls.” https://jina.ai/news/auto-gpt-unmasked-hype-hard-truths-production-pitfalls/
[3] Karthik Valmeekam, Alberto Olmo, Sarath Sreedharan, and Subbarao Kambhampati. 2022. “Large Language Models Still Can’t Plan (A Benchmark for LLMs on Planning and Reasoning about Change).” http://arxiv.org/abs/2206.10498
[4] Yoav Goldberg. 2023. “Some remarks on Large Language Models.” https://gist.github.com/yoavg/59d174608e92e845c8994ac2e234c8a9 (prev. discussion: https://www.linkedin.com/posts/benjaminhan_llms-chatgpt-reasoning-activity-7016123408799203328-2iJS)