LLMs, Copyrighted Training Data, and Fair Use

Behind the power of generative AI lies LLMs trained on potentially copyrighted material. How do we decide which scenarios fall under the concept of Fair Use (that permits use without a license)? How do we devise technical mitigations against improper use? Henderson et al from Stanford provides thorough considerations in their paper. Some of the highlights:
Fair Use defense depends on four factors (screenshot 1): (1) purpose of the use (2) nature of the copyrighted work (3) substantiality of the use, and (4) the effect of the use.
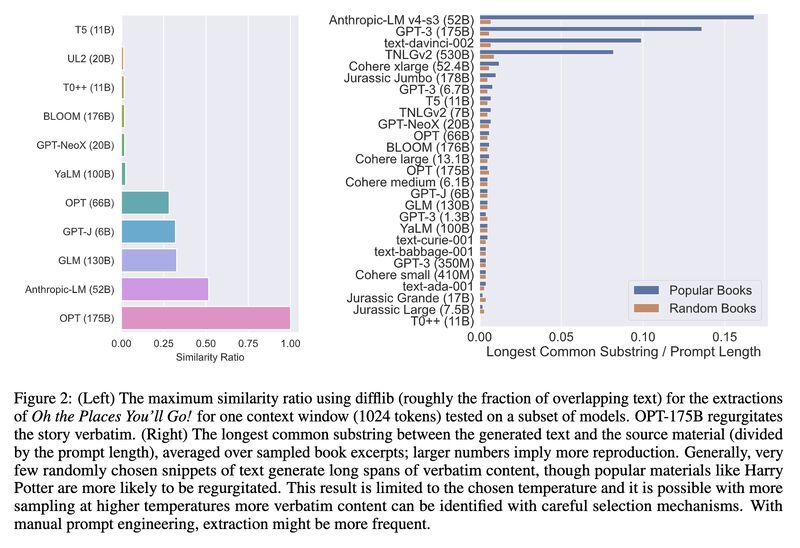
To test how much LLMs remember raw content, the authors prompted the models (#GPT3, BLOOM, AnthropicLM, Cohere etc) with samples of original texts/titles, and found memorization is more frequent with popular material/larger LLMs (screenshot 2).
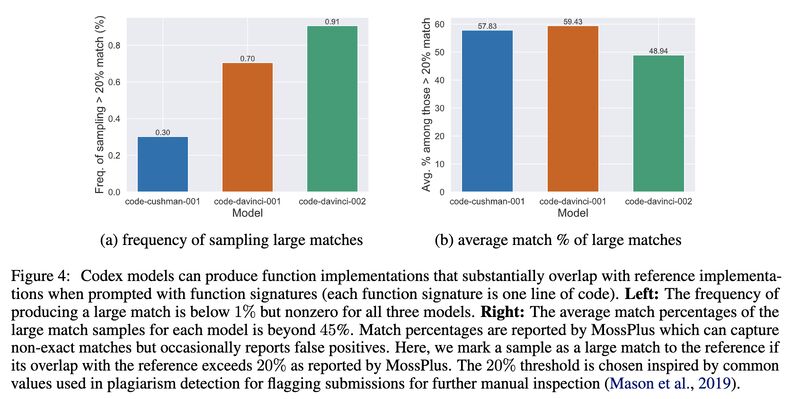
- Similarly they prompted Codex with function signatures and found substantial overlaps between the generated implementations and the references (screenshot 3).
DMCA safe harbors may not apply to generated content.
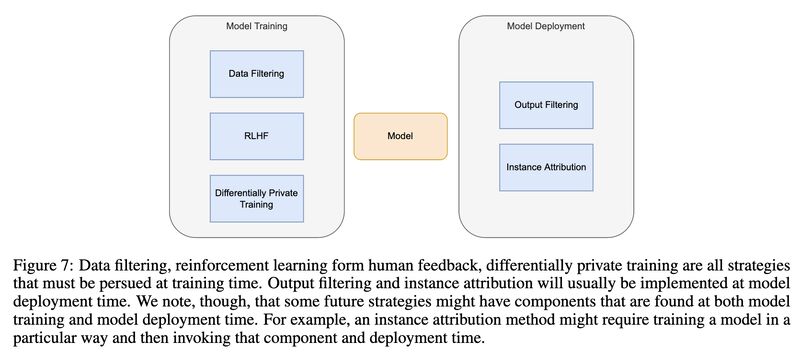
Three technical mitigations are proposed: (1) output filtering (2) instance attribution (3) differentially private training (screenshot 4 & 5).
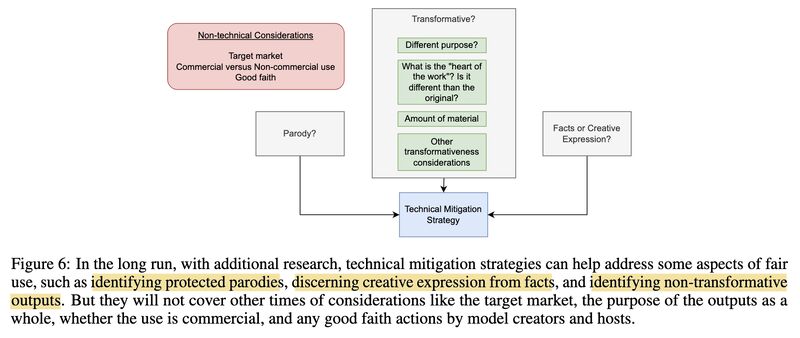
Peter Henderson, Xuechen Li, Dan Jurafsky, Tatsunori Hashimoto, Mark Lemley, and Percy Liang. 2023. Foundation Models and Fair Use. [1]
(On Mastodon)
Originally posted on LinkedIn.
References
[1] Peter Henderson, Xuechen Li, Dan Jurafsky, Tatsunori Hashimoto, Mark Lemley, and Percy Liang. 2023. “Foundation Models and Fair Use.” https://arxiv.org/abs/2303.15715