Why Does In-Context Learning Work? Gradient Descent and PAC Learnability
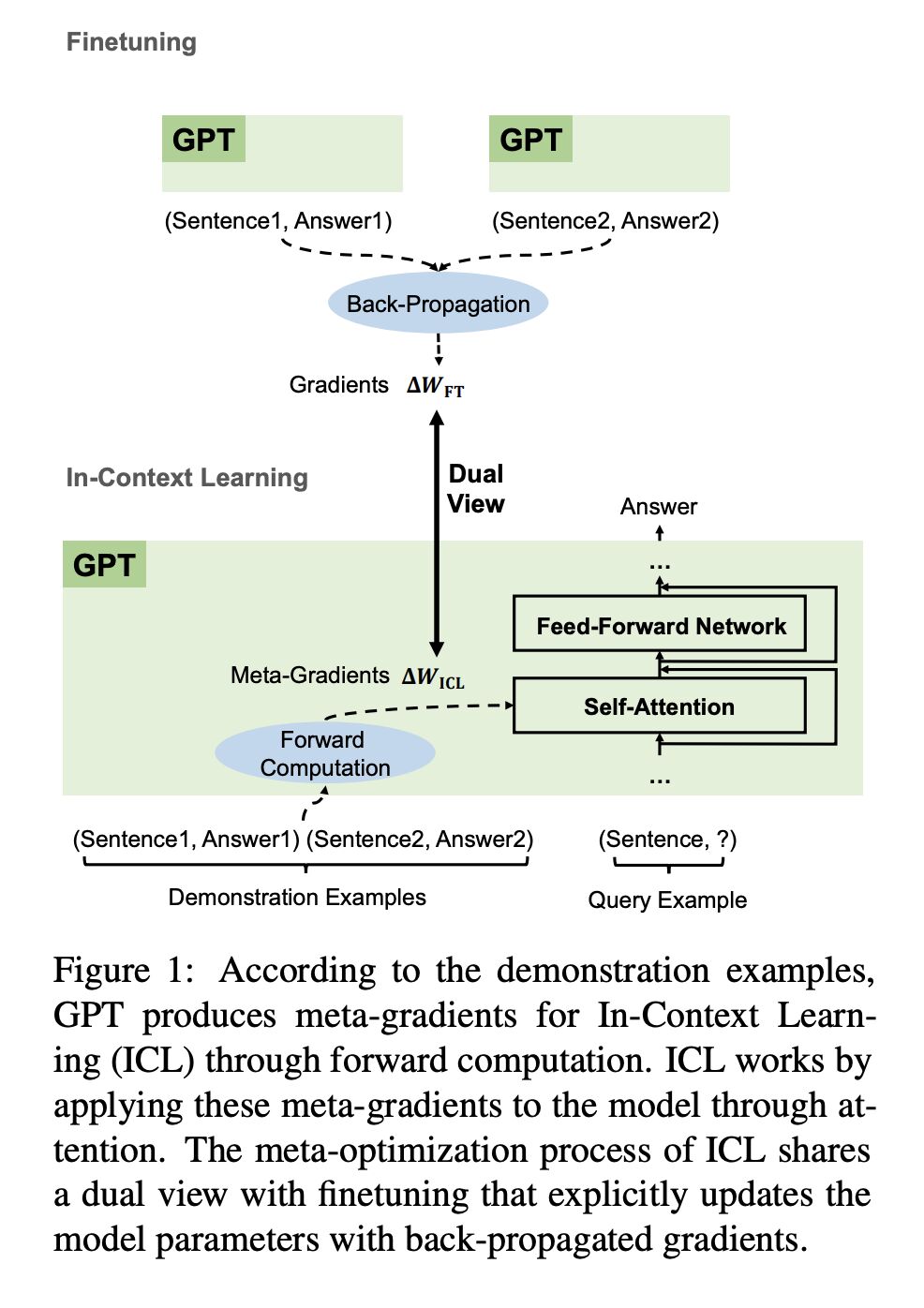
In the age of generative AI and GPT-4, two recent papers investigate a fundamental question: why does In-Context Learning (ICL) work? Why can a frozen LLM learn a new task by just receiving a list of demonstrations even when the task has not been explicitly pretrained?
Paper 1 shows ICL works because the attention mechanism is secretly performing gradient descent (screenshot 1 and 2)! Although the LM is frozen, including the W_Q, W_K and W_V projection matrices, attention on the demonstration tokens are not (screenshot 3).


Paper 2 shows ICL is PAC (Probably Approximately Correct) learnable (see screenshot 4 & 5 for definition and the final theorem). The intuition is that LLM undergoing pretraining already learned a mixture of latent tasks, and prompts (demonstrations) serve to identify the task at hand rather than “learning” it. The proof requires 4 assumptions, with the most important one being that pretraining distributions are efficiently learnable (screenshot 6).



Originally posted on LinkedIn.
References
[1] Damai Dai, Yutao Sun, Li Dong, Yaru Hao, Zhifang Sui, and Furu Wei. 2022. “Why Can GPT Learn In-Context? Language Models Secretly Perform Gradient Descent as Meta-Optimizers.” http://arxiv.org/abs/2212.10559
[2] Noam Wies, Yoav Levine, and Amnon Shashua. 2023. “The Learnability of In-Context Learning.” http://arxiv.org/abs/2303.07895