How Close Is ChatGPT to Human Experts? Human Evaluations and Detection
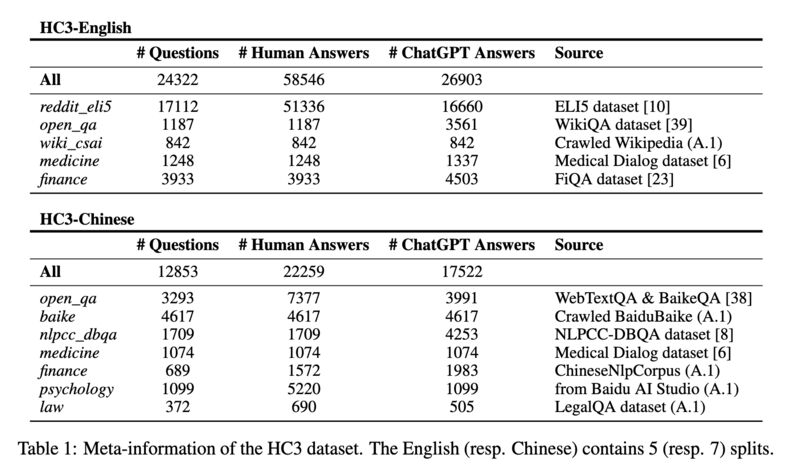

Interesting paper comparing how distinguishable the answers from ChatGPT and how helpful they are compared to those from humans when the same set of questions are asked (screenshot 1 & 2):
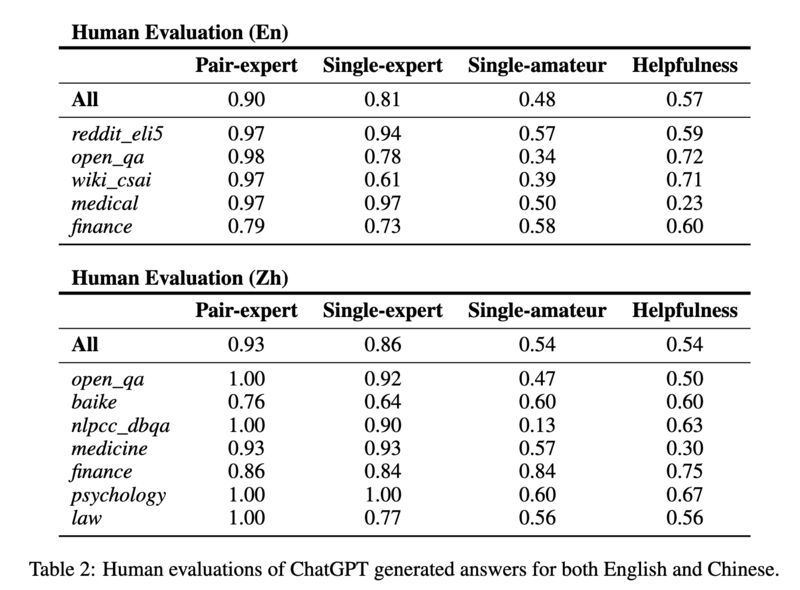
Human experts can detect ChatGPT-generated answers much more reliably than human amateurs (screenshot 3).
Slightly more than half of the times human experts found ChatGPT-generated answers are helpful (screenshot 3).
ChatGPT is more helpful in finance and psychology, and least in medical (screenshot 3).
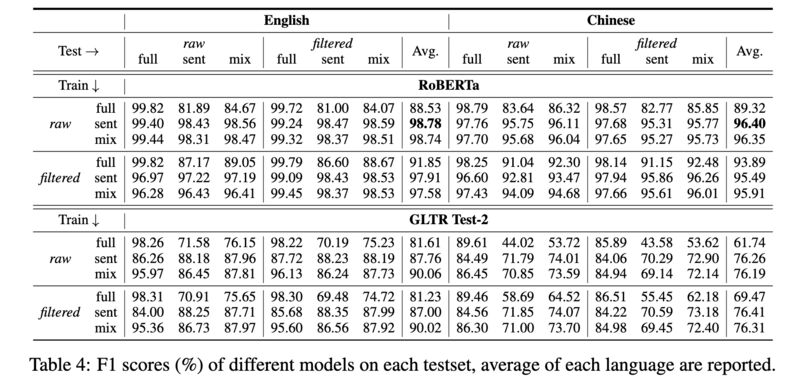
RoBERTa-based classifier can reliably detect ChatGPT-generated answers(96+ in F1; screenshot 4).
Biyang Guo, Xin Zhang, Ziyuan Wang, Minqi Jiang, Jinran Nie, Yuxuan Ding, Jianwei Yue, and Yupeng Wu. 2023. “How Close Is ChatGPT to Human Experts? Comparison Corpus, Evaluation, and Detection.” arXiv [cs.CL]. [1]
Abstract: The introduction of ChatGPT has garnered widespread attention in both academic and industrial communities. ChatGPT is able to respond effectively to a wide range of human questions, providing fluent and comprehensive answers that significantly surpass previous public chatbots in terms of security and usefulness. On one hand, people are curious about how ChatGPT is able to achieve such strength and how far it is from human experts. On the other hand, people are starting to worry about the potential negative impacts that large language models (LLMs) like ChatGPT could have on society, such as fake news, plagiarism, and social security issues. In this work, we collected tens of thousands of comparison responses from both human experts and ChatGPT, with questions ranging from open-domain, financial, medical, legal, and psychological areas. We call the collected dataset the Human ChatGPT Comparison Corpus (HC3). Based on the HC3 dataset, we study the characteristics of ChatGPT’s responses, the differences and gaps from human experts, and future directions for LLMs. We conducted comprehensive human evaluations and linguistic analyses of ChatGPT-generated content compared with that of humans, where many interesting results are revealed. After that, we conduct extensive experiments on how to effectively detect whether a certain text is generated by ChatGPT or humans. We build three different detection systems, explore several key factors that influence their effectiveness, and evaluate them in different scenarios. The dataset, code, and models are all publicly available at [2].
Originally posted on LinkedIn.
References
[1] Biyang Guo, Xin Zhang, Ziyuan Wang, Minqi Jiang, Jinran Nie, Yuxuan Ding, Jianwei Yue, and Yupeng Wu. 2023. “How Close Is ChatGPT to Human Experts? Comparison Corpus, Evaluation, and Detection.” arXiv [cs.CL]. http://arxiv.org/abs/2301.07597
[2] https://github.com/Hello-SimpleAI/chatgpt-comparison-detection