Curriculum NLI @ NAACL 2022: Where Models Fail
NLP
NLU
knowledge graphs
NAACL
conference
paper
Curriculum NLI at NAACL 2022 — a sobering look at lexical/logical/commonsense/comprehension fail-modes. Knowledge graphs should help.
A few months ago I posted my summary of this excellent paper, which was presented earlier today in NAACL2022 (my earlier post, Michael Witbrock):
Zeming Chen, and Qiyue Gao. 2022. “Curriculum: A Broad-Coverage Benchmark for Linguistic Phenomena in Natural Language Understanding.” arXiv [cs.CL]. arXiv. http://arxiv.org/abs/2204.06283.
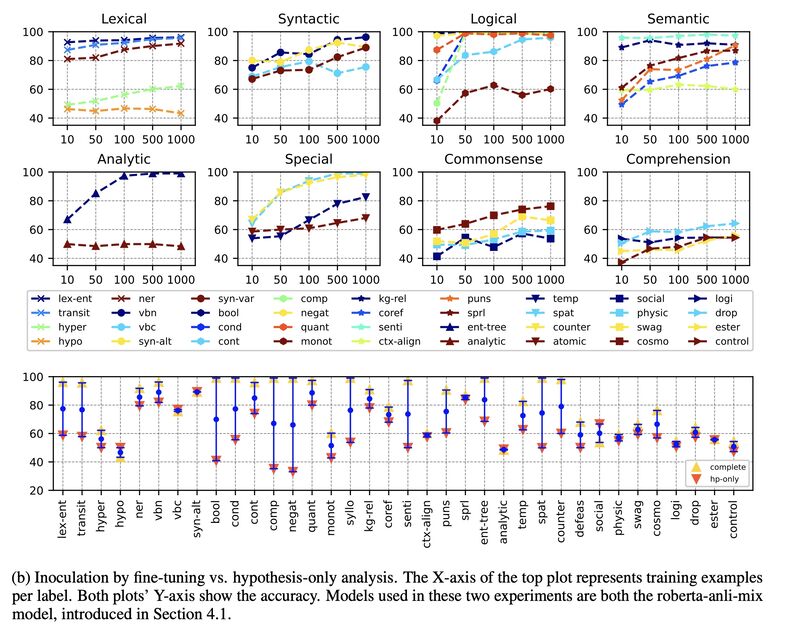
Looking again at the current-gen NLI fail modes evident in the charts, it’s worth singling out those tasks where the learning curves fall much short of expectation:
- Lexical -> hyper (hypernymy): https://arxiv.org/abs/1912.13337
- Lexical -> hypo (hyponymy): https://arxiv.org/abs/1912.13337
- Logical -> bool (boolean): https://arxiv.org/abs/1909.07521
- Semantic -> ctx-align (context alignment): https://aclanthology.org/I17-1100/
- Analytic -> analytic (analytical reasoning): https://arxiv.org/abs/2104.06598
- Special -> atomic (defeasible reasoning): https://aclanthology.org/2020.findings-emnlp.418/
- Commonsense -> social: https://aclanthology.org/D19-1454/
- Commonsense -> physic (physical): https://arxiv.org/abs/1911.11641
- Commonsense -> swag (HellaSwag): https://arxiv.org/abs/1811.00146
- Comprehension -> logi (deductive reasoning): https://arxiv.org/abs/2007.08124
- Comprehension -> drop (discrete reasoning): https://aclanthology.org/N19-1246/
- Comprehension -> ester (event semantic reasoning): https://arxiv.org/abs/2104.08350
- Comprehension -> control (contextual reasoning): https://ojs.aaai.org/index.php/AAAI/article/view/17580
It’s sobering that the current tech can’t even get lexical phenomena right. This is where KnowledgeGraph can potentially help.
Originally posted on LinkedIn.