Curriculum: A Broad-Coverage NLI Benchmark
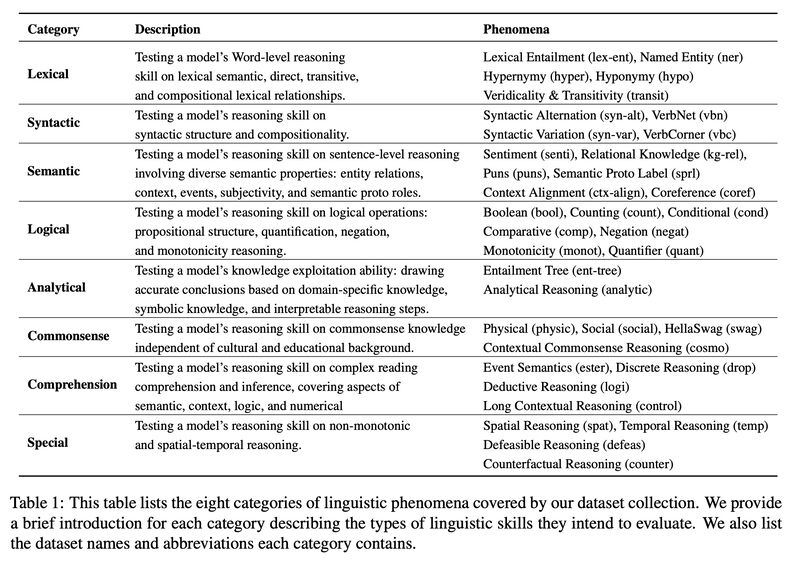
Great NAACL2022 paper examining NLI (natural language inference) through 4 tests (Zero-shot, inoculation, hypothesis-only and cross-distribution generalization), 8 linguistic categories (lexical, syntactic, semantic, logical, analytical, commonsense, comprehension and special; Table 1) and two difficulty distributions via Pointwise V-information.
Top of Fig. 3 shows for some categories the models just can’t learn through more examples, e.g., monot (monotonicity) and logi (deductive reasoning).
Bottom of Fig. 3 shows for certain categories, the models perform the same or even better with hypotheses only! For high-accuracy tasks this indicates overfitting, and for low-accuracy ones this shows the difficulty of the categories – either the data is noisy (adding premises actually hurt), or the models are inadequate.
Fig. 4 shows in many categories the models can’t generalize across two different distributions. In particular it’s harder to generalize from “hard” distribution to “simple” because the datasets in the former contain less useful information.
Zeming Chen and Qiyue Gao. 2022. “Curriculum: A Broad-Coverage Benchmark for Linguistic Phenomena in Natural Language Understanding.” arXiv [cs.CL]. arXiv. http://arxiv.org/abs/2204.06283.
Abstract: In the age of large transformer language models, linguistic evaluation play an important role in diagnosing models’ abilities and limitations on natural language understanding. However, current evaluation methods show some significant shortcomings. In particular, they do not provide insight into how well a language model captures distinct linguistic skills essential for language understanding and reasoning. Thus they fail to effectively map out the aspects of language understanding that remain challenging to existing models, which makes it hard to discover potential limitations in models and datasets. In this paper, we introduce Curriculum as a new format of NLI benchmark for evaluation of broad-coverage linguistic phenomena. Curriculum contains a collection of datasets that covers 36 types of major linguistic phenomena and an evaluation procedure for diagnosing how well a language model captures reasoning skills for distinct types of linguistic phenomena. We show that this linguistic-phenomena-driven benchmark can serve as an effective tool for diagnosing model behavior and verifying model learning quality. In addition, Our experiments provide insight into the limitation of existing benchmark datasets and state-of-the-art models that may encourage future research on re-designing datasets, model architectures, and learning objectives.
Originally posted on LinkedIn.