International Mother Language Day: Multilingual Sprachbund
On this InternationalMotherLanguageDay, here is an interesting paper from Microsoft on multilingual representation.
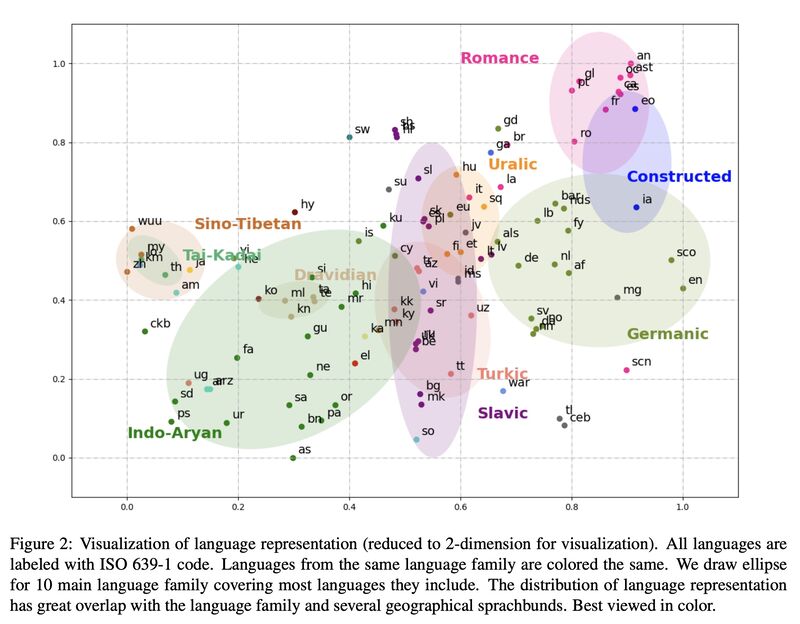
Simple clustering over centroids of multilingual sentence representation yields “Sprachbunds” (or Sprachbünde?) that closely align with language families resulted from linguistic analyses (Ethnologue). The clusters also align with Geographical Sprachbund: Romance/Germanic on the top-right, Indo-Aryan/Dravidian/Sino-Tibetan on the bottom-left, and Turkic/Uralic/Mongolic in the middle.
Continuously pre-training representation sprachbunds further improves multilingual downstream tasks, benefiting especially the lower-resourced languages.
Yimin Fan, Yaobo Liang, Alexandre Muzio, Hany Hassan Awadalla, Houqiang Li, Ming Zhou, and Nan DUAN. 2021. “Discovering Representation Sprachbund For Multilingual Pre-Training.” arXiv. http://arxiv.org/abs/2109.00271
Abstract: Multilingual pre-trained models have demonstrated their effectiveness in many multilingual NLP tasks and enabled zero-shot or few-shot transfer from high-resource languages to low resource ones. However, due to significant typological differences and contradictions between some languages, such models usually perform poorly on many languages and cross-lingual settings, which shows the difficulty of learning a single model to handle massive diverse languages well at the same time. To alleviate this issue, we present a new multilingual pre-training pipeline. We propose to generate language representation from multilingual pre-trained models and conduct linguistic analysis to show that language representation similarity reflect linguistic similarity from multiple perspectives, including language family, geographical sprachbund, lexicostatistics and syntax. Then we cluster all the target languages into multiple groups and name each group as a representation sprachbund. Thus, languages in the same representation sprachbund are supposed to boost each other in both pre-training and fine-tuning as they share rich linguistic similarity. We pre-train one multilingual model for each representation sprachbund. Experiments are conducted on cross-lingual benchmarks and significant improvements are achieved compared to strong baselines.
Originally posted on LinkedIn.