Saliency vs Attention: Eye-Tracking Says Saliency Wins
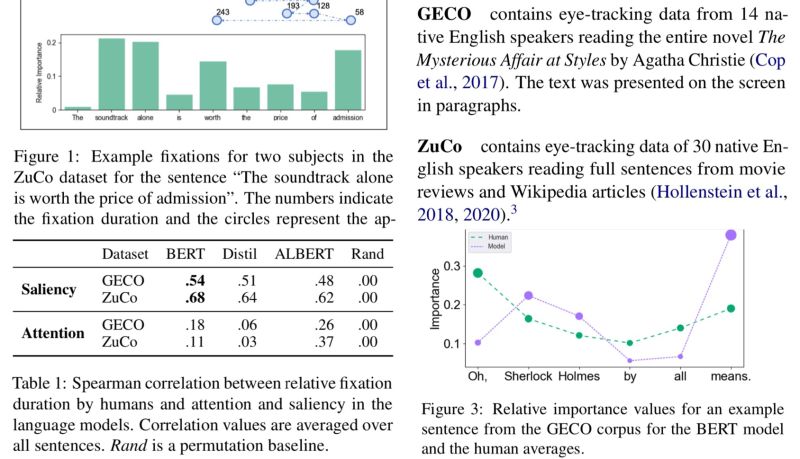
Interesting paper showing fixation duration obtained from eye tracking (Fig. 1) correlates better to salience-based rather than attention-based importance obtained from BERT (Table 1). This result gives cognitive-based support for the other works with similar conclusion from purely computational side.
One question is how the model-based importance was computed since the reading tasks were done on books/long articles (GECO & ZuCo) while BERT usually is used with input length limit. This is brought up in Fig. 3 about “Sherlock Holmes”: in book settings the fixation duration is much reduced because of the high frequency of the words, but such effect should be much reduced for BERT-based importance due to input length limit.
Since this shows cognitive attention is different from the computational attention and the former correlates better with salience (gradients) — a model-intrinsic and faithful metric — the current implementation of self-attention in transformers, while effective, might not be an optimal approach.
Nora Hollenstein and Lisa Beinborn, 2021. “Relative Importance in Sentence Processing.” ArXiv [Cs.CL]. arXiv. http://arxiv.org/abs/2106.03471.
Abstract: Determining the relative importance of the elements in a sentence is a key factor for effortless natural language understanding. For human language processing, we can approximate patterns of relative importance by measuring reading fixations using eye-tracking technology. In neural language models, gradient-based saliency methods indicate the relative importance of a token for the target objective. In this work, we compare patterns of relative importance in English language processing by humans and models and analyze the underlying linguistic patterns. We find that human processing patterns in English correlate strongly with saliency-based importance in language models and not with attention-based importance. Our results indicate that saliency could be a cognitively more plausible metric for interpreting neural language models. The code is available on GitHub: this https URL
Originally posted on LinkedIn.